Haskell for commercial software development
February 02, 2016 | Mike Craig
Inquiring minds on Quora want to know, is Haskell suitable for commercial software development?
I’m looking for an alternative to Python mainly for reasons of Python having so much trouble with workable concurrency, and Go seemed great at first look (it’s still not bad, but indeed error handling and lack of generics are a few features cut away too far).
This pretty much leaves Haskell as workable alternative. But is it really a practical alternative?
My biggest fear that while Haskell seems very powerful, it is also difficult and so it may be too difficult for person A to read code written by person B (what seems to have killed Lisp in my view is that problem and person-specific DSLs written in Lisp were simply unreadable for too many other people).
PS, in other words: I do not ask about strong sides of Haskell (or language X), those are well known, but rather about a lack of show-stoppers.
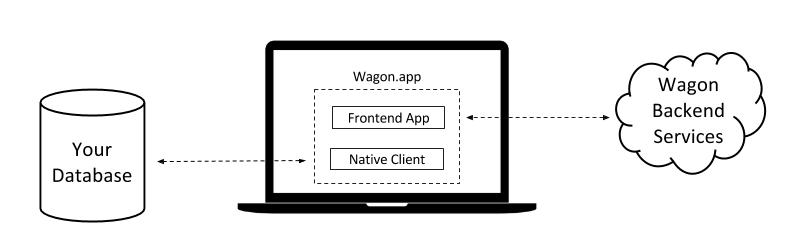
Absolutely, yes! At Wagon, we’ve built server- and client-side systems in Haskell, running in AWS and distributed to our users in a cross-platform desktop app.

Possible show-stoppers to using Haskell commercially:
Community support
A good open-source community is a big deal. It’s the difference between fixing other people’s code and finding an open GitHub issue with a workaround and an in-progress fix. With Haskell, we find the latter much more frequently than the former. The community is positive, active, and generally helpful when problems come up. Lively discussion takes place on Reddit, IRC, a public Slack channel, and several mailing lists.
Hiring
There are many factors involved in hiring: team size, location, remove vs on-site, other expertise required, etc. At Wagon we’re an on-site team of ~10 in San Francisco, with lots of web- and database-related problems to work on. Finding qualified Haskellers has not been an issue.
Haskell is different from the languages lots of developers are used to. ML-style syntax, strong types, and lazy evaluation make for a steep initial learning curve. Anecdotally, we’ve found Haskell’s secondary learning curve smooth and productive. Intermediate Haskellers quickly pick up advanced concepts on the job: parsers, monad transformers, higher-order types, profiling and optimization, etc.
Available industrial-strength libraries
Haskell lends itself to lightweight-but-powerful libraries that do one thing very well. We get a lot done by composing these small libraries rather than relying on big feature-complete frameworks. Some libraries have become de-facto standards that are stable and performant, and Stackage gives us a reliable way to find additional packages that usually “just work”.
We do sometimes find gaps in Haskell’s available libraries. For example, Haskell can’t yet match Python’s tools for numerical computing. And like every open-source ecosystem, there is some bad code out there. We rely on community recommendations and a sense of dependency hygiene to stay productive.
Performance
A quick Google search turns up benchmarks comparing Haskell to anything else you can imagine. In practice, we’re interested in tools with two properties:
- Fast enough under most circumstances. “Fast enough” means performance is never an issue for a given piece of code.
- Easy to optimize when needed. When we do need more speed, we’d like to get it incrementally rather than immediately rewrite that code in C.
Haskell has both of these properties. We almost never have to address performance in our Haskell code. When we do, we turn to GHC’s profiler and its many performance knobs: optimization flags, inlining, strictness and memory layout controls, etc. Haskell also has good interopability with C for when that’s appropriate.
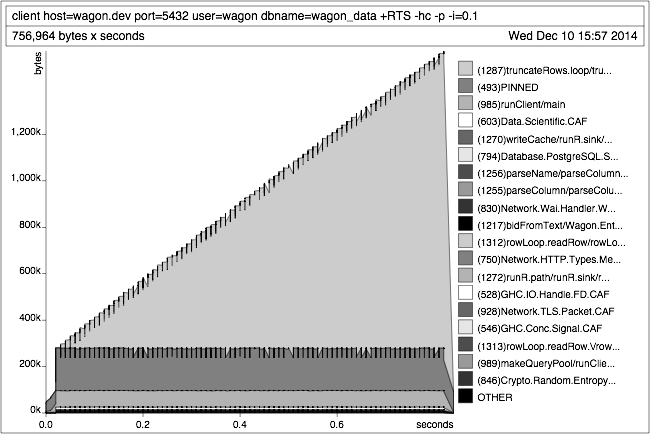
Memory leaks
There’s a lot of talk about memory leaks caused by Haskell’s lazy evaluation model. We run into this very infrequently in practice, and in those rare situations GHC’s profiler has led us to solutions quickly. The real problem is not lazy evaluation but lazy IO, which we avoid with tools like conduit and pipes.
Debuggability
Haskell doesn’t have a debugger in the same sense as Python or Java. This is mostly a non-issue, because exceptions are rare and GHCi gives us a flexible way to run code interactively. Nonetheless, hunting down problems in a big application can be difficult. This has improved in recent versions of GHC with support for proper stack traces.
Haskellers reading other Haskellers’ code
This hasn’t been a problem for us. Haskell is a flexible language both in syntax and semantics, but this leads to better solutions more than it leads to opaque or unreadable code. Heavy indirection—via embedded DSLs or deep typeclass hierarchies—is unusual in practice. We reach for those tools as a last resort, knowing that they come with a serious maintenance cost. Agreeing on a basic style guide helps smooth out minor syntax differences.
Read our other Haskell engineering blog posts, come to our community events, or better yet, join our team!